 Arrête ton char Langues & Cultures de l'Antiquité
Arrête ton char Langues & Cultures de l'Antiquité
Le lexique fréquentiel, qui ne retient que les mots dont les occurrences sont les plus nombreuses, est un outil important pour que les efforts d’apprentissage que l’on fournit soient efficacement dirigés : l’objectif est de retenir les termes que l’on rencontre le plus fréquemment, afin de renforcer leur ancrage dans la mémoire et d’obtenir la satisfaction de constater régulièrement l’intérêt d’un tel apprentissage.
Quelques ouvrages existent, pour le grec ancien, qui fournissent un corpus de termes répondant à ce critère fréquentiel, mais qui les classent suivant une logique différente de celle qui nous intéressait : généralement, l’organisation des mots est alphabétique et étymologique (Les Mots grecs de F. Martin) ou thématique (Vocabulaire grec de base de S. Byl, Vocabulaire grec de J. Bertrand) ; elle peut aussi se fonder sur une anthologie restreinte de textes (Vocabulaire grec commenté et sur textes de V. Fontoynont). Malgré l’intérêt de ces approches, nous souhaitions disposer d’une liste qui ordonne les mots en fonction de la seule fréquence de leur emploi, du plus fréquent au moins usité, afin d’en faire le premier critère de planification des apprentissages lexicaux de nos élèves.
Un ancien ouvrage propose de telles tables fréquentielles : le Vocabulaire de base du grec de G. Cauquil et J.-Y. Guillaumin (la « liste hiérarchique » commence à la p. 151). Son inconvénient majeur, à mon sens, vient du fait qu’il est fondé sur un corpus d’auteurs triplement trop restreint pour nos besoins : peu d’auteurs sont concernés (Andocide, Antiphon, Lysias, Démosthène, Isocrate, Euripide, Xénophon), sur une trop faible étendue chronologique et sans réelle variété générique.
Nous avons donc souhaité établir une nouvelle base de données, qu’on trouvera ci-dessous ; elle retient un nombre de mots comparable à certains des ouvrages cités précédemment (1507 mots, contre les 1600 de G. Cauquil et J.-Y. Guillaumin ou les 1700 de S. Byl, issus d’extraits relativement brefs d’Hérodote, Thucydide, Platon, Xénophon et Lucien). Cependant, puisque le fichier Excel auquel nous avons abouti classe les 5670 mots différents qui apparaissent dans l’ensemble du corpus des 23 auteurs sélectionnés, chaque utilisateur intéressé pourra augmenter ce total en modifiant les règles de calcul qui ont permis de l’établir.
Méthode pour la constitution de la liste
- Auteurs retenus :
- Nous avons sélectionné la liste de tous les auteurs dont des extraits ont été choisis pour les sujets de l’écrit (versions) et de l’oral (traductions et commentaires) du concours de l’ENS de Lyon entre 2013 et 2023 : du fait que ce concours est prévu pour des étudiants n’ayant étudié le grec que pendant deux années seulement, les textes et auteurs choisis sont plutôt représentatifs de ce qu’on peut attendre d’un helléniste en début de formation. (En outre, cette sélection a le mérite de tenir compte de tous les genres et ne se limite pas à l’époque classique, qui n’est pas la seule dont on attend la fréquentation.)
- Les auteurs qui ont été retenus plus de deux fois pour ce concours bénéficient d’un coefficient 2 dans les calculs :
- coeff. 2 : Aristophane, Euripide, Hérodote, Homère, Lucien, Lysias, Plutarque, Sophocle, Xénophon, Platon ;
- coeff. 1 : Aristote, Basile de Césarée, Démosthène, Eschine, Eschyle, Ésope, Hésiode, Hypéride, Isocrate, Jean Chrysostome, Longus, Lycurgue, Théocrite.
- Source du lexique fréquentiel propre à chaque auteur :
- C’est le Thesaurus Linguae Graecae qui nous a fourni chacune des listes. Nous n’avons pas sélectionné des oeuvres précises, mais la totalité du corpus de chaque auteur, même les oeuvres fragmentaires (faute de temps pour les extraire…).
- Cet outil présente deux inconvénients majeurs, dont il faut tenir compte dans la planification des apprentissages :
- il ne prend pas en considérations les mots surreprésentés, qu’il faut veiller à faire apprendre par ailleurs (ou que l’on rencontre très rapidement ou spécifiquement, de toute façon) : αὐτός, γάρ, δέ, ἐγώ, εἰμί, καί, μέν, οὐ, οὗτος, ὅς, etc. ;
- ses nombres d’occurrences comportent quelques inexactitudes parce que certains mots peuvent être doublement analysés par le programme (par exemple, ἀγαθῷ est certainement comptabilisé à la fois pour les entrées « ἀγαθόν, ‑οῦ (τό) » et « ἀγαθός, ‑ή, ‑όν »).
- S’y ajoute une autre difficulté, en fait : les listes téléchargeables ne comprennent que les 1000 mots les plus fréquents d’un auteur donné, si bien que certains sont faussement indiqués comme absents dans nos tableaux (cela ne joue qu’un rôle mineur, cependant, dans le classement).
- Règles de calcul :
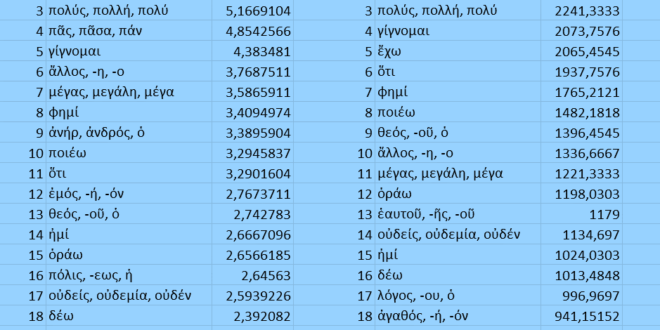
- Pour ne pas donner plus d’importance aux auteurs dont nous avons conservé un plus grand nombre de textes, les calculs tiennent compte de la fréquence de chaque mot au sein du corpus propre à chaque auteur. (Une autre logique, qui a aussi son intérêt, consisterait à prendre en considération les nombres d’occurrences absolus : nous les indiquons aussi pour information ; d’ailleurs, il se trouve que les mots des deux listes sont strictement identiques : seul le ordre change !).
- Cette fréquence est calculée ainsi : le nombre d’occurrences d’un mot dans les textes d’un auteur est divisé par le nombre total de mots qu’on y trouve.
- L’indice de fréquence qui permet d’ordonner les mots correspond à la moyenne de ces fréquences (coefficientée) pour tous les auteurs.
- Sont exclus tous les mots qui ne sont pas présents parmi au moins 4 des 23 auteurs et parmi au moins 2 des 10 auteurs de la première liste. L’objectif est de viser la lecture d’un maximum d’auteurs.
- Deux exemples :
- ὀνειδίζω apparaît au rang 1330 dans l’ouvrage de G. Cauquil et J.-Y. Guillaumin, 1500 dans notre classement par fréquences, 1507 dans le classement par quantités (ce verbe n’est utilisé que par quatre auteurs de notre corpus : Ésope, Isocrate, Lysias et Sophocle ; chaque fois, il compte entre 8 et 15 occurrences seulement) ;
- ὄνομα, ‑ματος (τό) apparaît au rang 256 dans l’ouvrage de G. Cauquil et J.-Y. Guillaumin, 112 dans notre classement par fréquences, 101 dans le classement par quantités (ce verbe est utilisé par tous les auteurs de notre corpus à l’exception de trois : Homère [en fait, il apparaît 22 fois, mais cette faible représentation le place au-delà des 1000 premiers mots], Hésiode [en fait, 3 fois] et Ésope [en fait, 7 fois] ; chaque fois, il compte entre 7 et 2461 occurrences).
Fichier à télécharger : contenu et manipulation
Le fichier .xlsx joint comprend la totalité des informations dont nous avons eu besoin pour obtenir la liste finale : il comporte donc de nombreux onglets, qu’il n’est pas indispensable de tous consulter… Nous les publions ici pour ceux qui souhaiteraient modifier les règles de calcul pour obtenir des résultats différents, plus adaptés à leurs besoins.
Que consulter ?
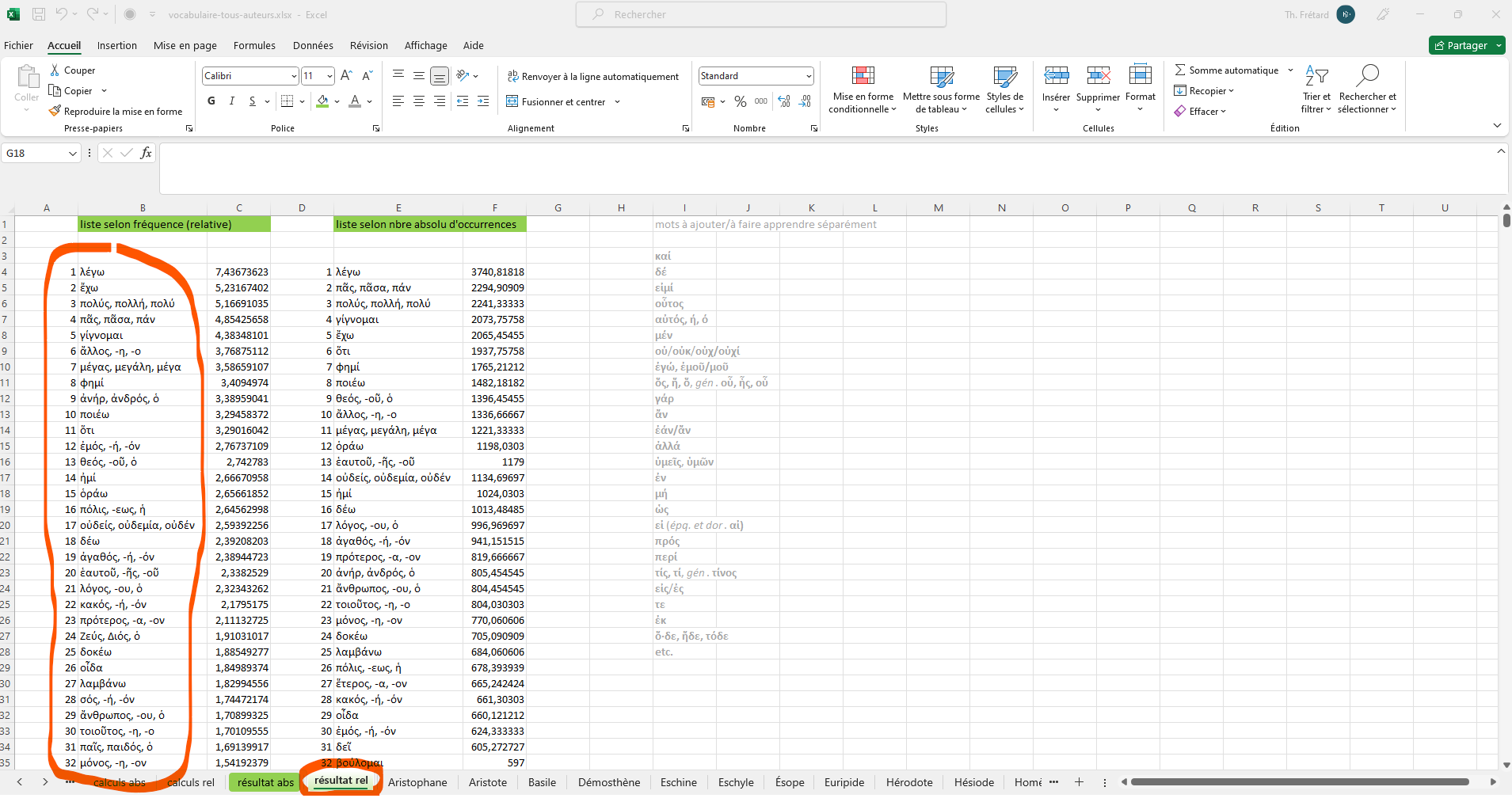
- Pour disposer uniquement de la liste de vocabulaire : onglet « résultat rel[atif] » (voir la capture d’écran ci-dessous).
- Pour modifier les règles de calcul, vous disposez de :
- une feuille de classeur par auteur (onglets 6 et suivants) ;
- deux onglets « calcul abs[olu] » et « calcul rel[atif] » qui tiennent compte respectivement du nombre d’occurrences par auteur et de la fréquence de celles-ci.
Comment l’utiliser ?
- Solution 1 : complétée (ou non) par une colonne comprenant les traductions, cette liste peut être distribuée directement aux élèves ; son étendue dépendra des choix de l’enseignant pour la planification de leurs apprentissages.
- Solution 2 : le fichier même peut être confié aux élèves à qui on demanderait de se constituer une liste de mots parmi ceux qui sont rencontrés dans les textes étudiés, au fur et à mesure de l’année ; il leur revient alors de de ne retenir que ceux qui figurent à la fois dans ces textes et dans cette liste.
- Solution 3 : …
C’est un outil qui reste perfectible : si vous avez des pistes pour améliorer cette production, n’hésitez pas à nous les signaler !
Mes remerciements à Aurélien, Corentin, François et Hugo pour leur soutien technique dans la recherche de la formule d’Excel qui m’échappait !
| Mise à jour du 23/07/2023 : Pour un aperçu de la manière dont on peut convertir ces données en document de travail, consultez la page « Vocabulaire grec fréquentiel pour les hellénistes débutants (2) : livret d’apprentissage« *. |


